

哈希冲突的解决方式
背景
一般来说,哈希表的实现是通过两个部分实现的
1 | hash = hashfunc(key) |
使用求模来减少存储空间,所以必然会导致不同的数据离散到相同的索引下标处,此时就发生了哈希冲突。
解决方案
主要分为两大类
- 链式法 (Separate Chaining)
- 开放地址法(Open Addressing)
链接技术将采用额外的数据节点来处理冲突。当冲突发生时,在冲突位置建立链表,通过链表串联起离散到相同下标的节点。在最坏的状况下,会退化为单链表,性能损失严重,哈希攻击便是采用这种形式。
开放地址就是开放哈希表中的所有地址,不使用额外的空间。如果遇到冲突,寻找其他位置存储。
开放地址法
线性探测
如果哈希到索引为 x 处,如果此处有元素,则查看 x + 1 处,如果没有则放在这里,如果有,则以此类推查看 x + 2,x + 3, …
二次探查
这是线性探测的改进,每次的步长变为平方倍数。
Double hashing
另一种改进的开放寻址法称为重哈希(Double hashing)或者叫二度哈希(Rehashing)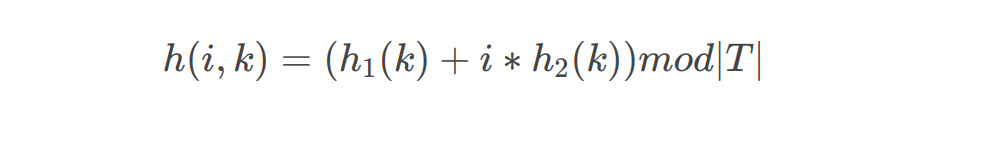
而在 LevelDB 中,只使用一个 hash 函数,通过移动步长来获得多个 hash 值,近似等价于使用 k 个哈希函数的效果。
1 | char* array = &(*dst)[init_size]; // 指针指向 Bit数组 的起始地址 |
标记逻辑位于
1 | for (size_t j = 0; j < k_; j++) { |
将生成的 hash 值取余得到对应的标记位。注意这里是标记 bit 位,由于是 char 数组,所以通过 array[bitpos / 8] 找到对应的char元素,再通过 1 << (bitpos % 8) 来标记这 8bit 中对应的位置。




