

DDIA-数据模型与查询语言
背景
数据模型可能是开发软件最重要的部分,它们不仅对软件的编写方式,而且还对如何解决问题都有深远的影响。
大多数应用程序是通过一层一层叠加数据模型来构建的。每一层都面临的关键问题是: 如何将其用下一层来表示? 例如:
- 作为一名应用程序开发人员,通过实际要求,创建对应的对象以及数据结构。
- 当需要存储这些数据结构时,可以采用通用数据模型 (例如JSON或XML文档、关系数据库中的表或图模型) 来表示。
- 数据库工程师接着决定用何种内存、磁盘或网络的字节格式来表示上述JSON/XML/关系/图形数据。数据表示需要支持多种方式的查询、搜索、操作和处理数据。
- 在更下一层,硬件工程师则需要考虑用电流、光脉冲、磁场等来表示字节。
复杂的应用程序可能会有更多的中间层,基于底层API来构建上层API,但是基本思想相同: 每层都通过提供一个简洁的数据模型来隐藏下层的复杂性。
下文将介绍一系列用于数据存储和查询的通用数据模型,我们将比较关系异型、文档模型和一些基于图的数据模型。我们还将讨论多种
查询语言并比较它们的使用场景。
关系模型与文档模型
SQL
现在最著名的数据模型可能是SQL,它基于Edgar Codd于1970年提出关系模型
数据被组织成关系 (relations) ,在SQL中称为表 (table) ,其中每个关系都是元组(tuples) 的无序集合(在SQL中称为行) 。
NoSQL
NoSQL 含义被解释为“不仅仅是SQL” 。
采用NoSQL数据库有这样几个驱动因素,包括:
- 比关系数据库更好的扩展性需求,包括支持超大数据集或超高写人吞吐量。
- 普遍偏受免费和开源软件而不是商业数据库产品。
- 关系模型不能很好地支持一些特定的查询操作。
对象-关系不匹配
现在大多数应用开发都采用面向对象的编程语言,如果数据存储在关系表中,那么应用层代码中的对象与表、行和列的数据库模型之间需要一个笨拙的转换层
关系映射 (ORM) 框架则减少了此转换层所需的样板代码量,但是他们并不能完全隐藏两个模型之间的差异。
例如采用JSON的形式表示简历

使用关系模型表示简历
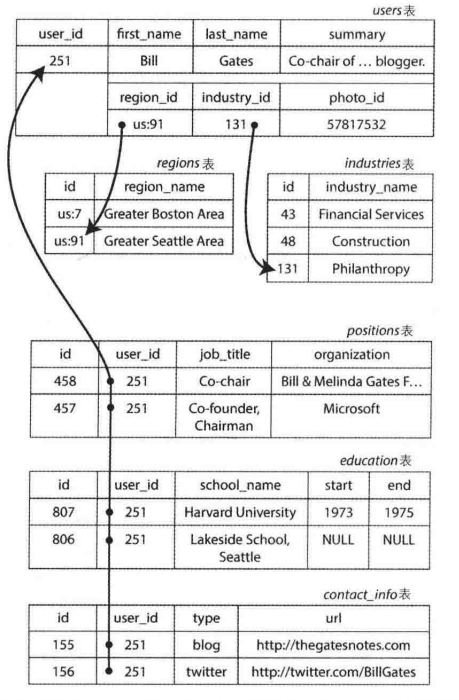
可以发现 JSON 比多表模式具有更好的局部性,多表模式需要连接多张表进行查询,而对于JSON,所有相关信息都存在一个地方,一次查询就足够了
所以对于这种一对多的模式,采用树状结构(层次模型)可以很好的表示
多对一与多对多
但是在表示多对一或者是多对多的关系时,就并不适合文档模型,但是对于关系数据库,由于支持连结操作,可以很方便地通过ID来引用其他表中的行
关系模型的优势:
- 结构简单: 所有数据以元组集合的形式存在,简化了数据处理,易于进行条件查询和数据更新。
- 查询优化: 关系数据库中的查询优化器自动处理查询执行顺序和索引使用,减轻了开发者负担
查询语言
- 查询语言的区别:
- 命令式查询(如IMS和CODASYL所用):要求程序明确每一步的执行过程,如遍历列表、检查条件等,类似于传统编程语言中的逻辑控制。
- 声明式查询(如SQL):只需指定想要的结果和必须满足的条件,不需要描述如何达到这个结果。这种方法由数据库的查询优化器自动决定执行策略。
- 实现差异的影响:
- 效率和简洁性:声明式查询因其简洁和直观而更易于编写和维护,尤其在处理复杂的数据结构和大量数据时。
- 性能优化:声明式查询允许数据库系统优化查询执行,如自动选择使用索引和联结,而命令式查询则固定了数据处理的步骤和顺序。
- 适用性与并行化:
- 命令式查询的限制:固定的执行顺序使得并行化处理变得复杂,不适合现代多核和分布式计算环境。
- 声明式查询的优势:更适合并行执行,因为它不指定操作的具体步骤,数据库可以自由地安排最有效的执行策略。
MapReduce 是一种介于命令式和声明式查询之间的编程模型,主要用于处理和生成大数据集。这种模型允许开发者通过两个主要的函数 map 和 reduce 来指定如何处理数据。
- Map 函数:处理输入数据,生成键值对作为中间结果。每个输入元素都由 map() 函数独立处理。
- Reduce 函数:对所有 map() 函数输出的键值对中具有相同键的值进行合并处理。这通常涉及求和、取平均或其他形式的聚合操作。
- 执行环境:MapReduce 通常在分布式系统上运行,允许在多个处理单元上并行执行 map() 和 reduce() 函数,优化处理效率。
系统自动处理数据的分片和分发,并管理各个节点间的数据流转。 - 适用场景:MapReduce 特别适合于需要对大量数据进行复杂处理的任务,比如大规模文本处理、日志文件分析和大型数据集的统计分析。
它的设计允许灵活地扩展到数百或数千台服务器。 - 优点:非常适合大规模数据处理,支持高度并行化操作,能够有效地利用分布式系统的计算资源。
缺点:编程模型相对固定,不如 SQL 灵活;对于一些简单查询或小数据量处理,可能会显得笨重。
图状数据模型
我们之前看到,多对多关系是不同数据模型之间的重要区别特征。如果数据大多是一对多关系(树结构数据) 或者记录之问没有关系,那么文档模型是最合适的。
但是,如果多对多的关系在数据中很常见呢? 关系模型能够处理简单的多对多关系,但是随着数据之间的关联越来越复杂,将数据建模转化为图模型会更加自然。
图由两种对象组成: 顶点 (也称为结点或实体) 和边 。很多数据
可以建模为图。典型的例子包括:
社区网络
顶点是人,边指示哪些人彼此认识。Web图
顶点是网页,边表示与其他页面的HTML链接。公路或铁路网
顶点是交叉路口,边表示他们之间的公路或铁路线。
小结
历史上,数据最初被表示为一棵大树(层次模型) ,但是这不利于表示多对多关系,所以发明了关系模型来解决这个问题。 最近,开发人员发现一些应用程序也不太适合关系模型。 新的非关系 “NoSQL” 数据存储在两个主要方向上存在分歧:
- 文档数据库的目标用例是数据来自于自包含文档,且一个文档与其他文档之间的关联很少。
- 图数据库则针对相反的场景,目标用例是所有数据都可能会互相关联。
所有这三种模型 (文档模型、关系模型和图模型) ,如今都有广泛使用,并且在各自的目标领域都足够优秀。我们观察到,一个模型可以用另一个模型来模拟。例如,图数据可以在关系数据库中表示,虽然处理起来比较策拙。这就是为什么不同的系统用于不同的目的,而不是一个万能的解决方案。
文档数据库和图数据库有一个共同点,那就是它们通常不会对存储的数据强加某个模式,这可以使应用程序更容易适应不断变化的需求。但是,应用程序很可能仍然假定数据具有一定的结构,只不过是模式是显式(写时强制) 还是隐式 (读时处理) 的问题。
1 | 模式的灵活性 |




