

DDIA-数据编码与演化
应用程序不可避免地需要随时间而变化,在演化过程中,需要不断地添加或修改功能。在大多数情况下,更改应用程序功能时,也需要更改其存储的数据: 可能需要捕获新的字段或记录类型,或者需要以新的方式呈现已有数据。
当数据格式发生变化时,经常需要对应用程序代码进行相应的调整(例如,向记录中添加新字段,然后应用程序代码开始读取和写入该字段) 。然而,对于一个大型应用系统,代码更迭往往并非易事。
- 服务器端程序,可能需要滚动升级,每次将新版本部署到少数几个节点,之后再逐步推广到所有节点。
- 对于客户端应用程序,用户可能不会在一段时间内马上更新软件
这意为着新旧版本的代码,以及新旧数据格式,可能同时在系统中共存,所以保证数据的双向兼容性至关重要
数据兼容性
- 向后兼容性
较新的代码可以读取由旧代码编写的数据 - 向前兼容性
较旧的代码可以读取新代码编写的数据
向后兼容通常不难实现:只需要清楚旧代码所编写的数据格式,就可以比较明确的处理这些数据,对于向前兼容性,旧的代码需要忽略新版本代码中所做的添加
在本文中,将介绍多种编码数据的格式,包括JSON、XML、Protocol Buffers、Thrift。特别地,我们将讨论它们如何处理模式变化,以及保证兼容性。之后,还将讨论这些格式如何用于数据存储和通信场景,包括在Web服务中,具象状态传输 (Representational State Transfer,REST) 和远程过程调用 (remote procedure calls,RPC) 以及消息传递系统,如actors和消息队列。
数据编码
程序通常使用两种不同的数据表示形式:
在内存中,数据保存在对象、结构体、列表、数组、哈希表和树等结构中。这些数据结构针对CPU的高效访问和操作进行了优化(通常使用指针) 。
将数据写和入文件或通过网络发送时,必须将其编码为某种自包含的字节序列(例如 JSON文档) 。由于指针对其他进程没有意义,所以这个字节序列表示看起来与内存中使用的数据结构大不一样。
因此,这两种表示之间需要进行类型的转化。从内存中的表示到字节序列的转化称为编码(或序列化等) ,相反的过程称为解码 (或解析,反序列化)。
语言特定的编码
多数编程语言,如Java、Ruby、Python等,通过内置库(例如Java的java.io.Serializable,Ruby的Marshal,Python的pickle)支持内存对象的编码。
这些库使得保存和恢复内存中的对象变得非常简单,仅需少量代码。但是却面临这一些问题与挑战:
- 编码与特定语言绑定:编码过程通常依赖于特定的编程语言,这使得使用其他语言访问编码数据变得困难,不利于跨语言或跨系统集成。
- 安全风险:解码过程可能允许实例化任意类,这可能导致安全漏洞,如远程执行代码。
- 版本兼容性问题:这些库通常忽略了数据的多版本兼容性,主要关注于数据编码的速度和简便性。
- 效率问题:编解码的CPU效率和编码结构的大小通常被忽视,特别是Java内置序列化因其性能不佳和庞大的编码结构而被批评。
尽管内置和第三方编码库在使用上非常方便,但由于上述问题,除非是临时尝试,语言内置的编码方案通常不是一个好方案。
JSON、XML与二进制变体
目标转向可由不同编程语言编写和读取的标准化编码,JSON 因为简单性以及在浏览器中内置支持而流行,并且它是javaScript的子集,XML 尽管被批评为复杂和冗长,但仍广泛使用。CSV 简单但功能有限,适用于基础数据表达。
JSON、XML和CSV都是文本格式,因此具有不错的可读性 (尽管语法容易引发争论) 。除了表面的语法问题之外,它们也有一些微妙的问题:
- 数字编码模糊性:XML和CSV难以区分数字和字符串;JSON区分数字和字符串,但不区分整数和浮点数,也不指定精度。
- 二进制数据不支持:JSON和XML不支持原生二进制数据,通常通过Base64编码解决,但这增加了数据大小和复杂性。
- 模式支持:XML和JSON的模式支持可选且复杂,而CSV完全没有模式支持,需手动管理数据结构的变化。
1
2
3XML使用XSD(XML Schema Definition)定义模式。XSD定义了XML文档的结构、元素和属性。
JSON模式(JSON Schema)定义了JSON数据的结构,包括哪些字段是必须的,它们的类型是什么,以及如何验证字段的值。
1 | // json 数据 |
1 | // JSON模式 |
尽管存在这些或那些缺陷,但JSON、XML和CSV已经可用于很多应用。特别是作为数据交换格式 (即将数据从一个组织发送到另一个组织)。
二进制编码
对于一个小的数据集来说,传输、解析的收益可以忽略不计,但一旦数据规模到达TB级别,就需要尽可能的压缩数据规模。减少编码大小。
对于特定的数据类型,上面的文本数据编码都不能很好的支持,所以需要一种支持不同数据类型的编码格式
为了解决上述的问题,来分析不同二进制编码之间是如何处理的

首先给出一个 JSON 编码的示例,后文将与该编码进行比对,看看不同编码格式的差异
Thrift 与 Protocol Buffers
Apache Thrift 和 Protocol Buffers (protobuf) 是基于相同原理的两种二进制编码库。Protocol Buffers 最初是在 Google 开发的,Thrift 最初是在 Facebook 开发的,二者都是开源的。
Thrift 和 Protocol Buffers 都需要模式来编码任意的数据。可以使用Thrift接口定义语言 (IDL) 来描述模式,如下所示:
1 | struct Person { |
Protocol Buffers的等价模式定义看起来非常相似:
1 | message Person { |
这两种数据编码通过在定义模式中指定数据类型来实现对不同数据的正确编码
那么这个模式编码的数据是什么样的呢? Thrift 有着两种不同的二进制编码格式,分别称为 BinaryProtocoal 与 CompactProtocal
先来看看 BinaryProtocol,这种格式编码需要59字节
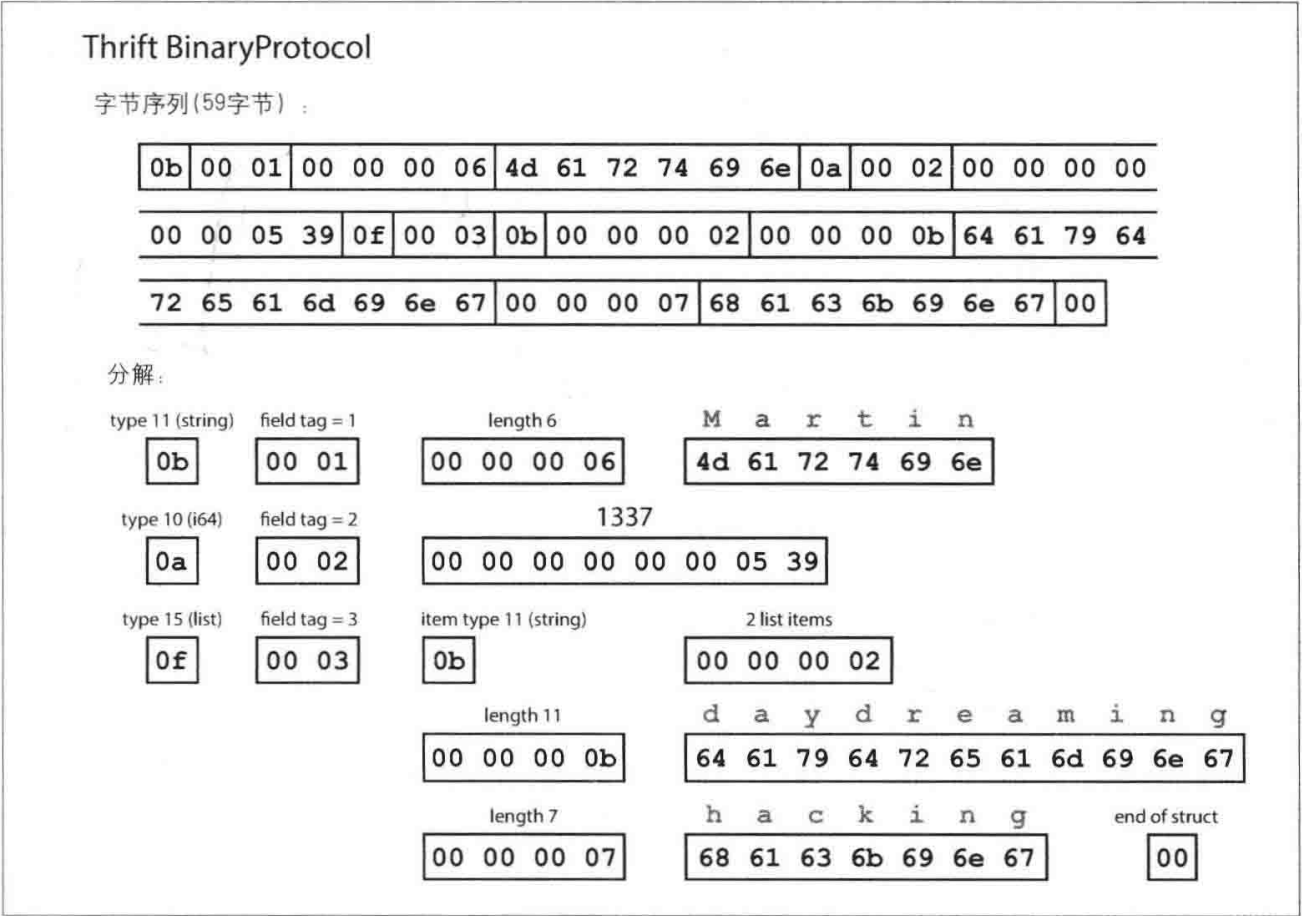
可以发现这种编码格式没有字段名 (userName、favoriteNumber和
interest) 。相反,确实包含这对应的数字标签(1、2和3),字段标签就像字段的别名,用来指示当前的字段,但更为紧凑。
Thrift CompactProtocol编码在语义上等同于BinaryProtocol,除了数字标签,还使用了变长数组来实现
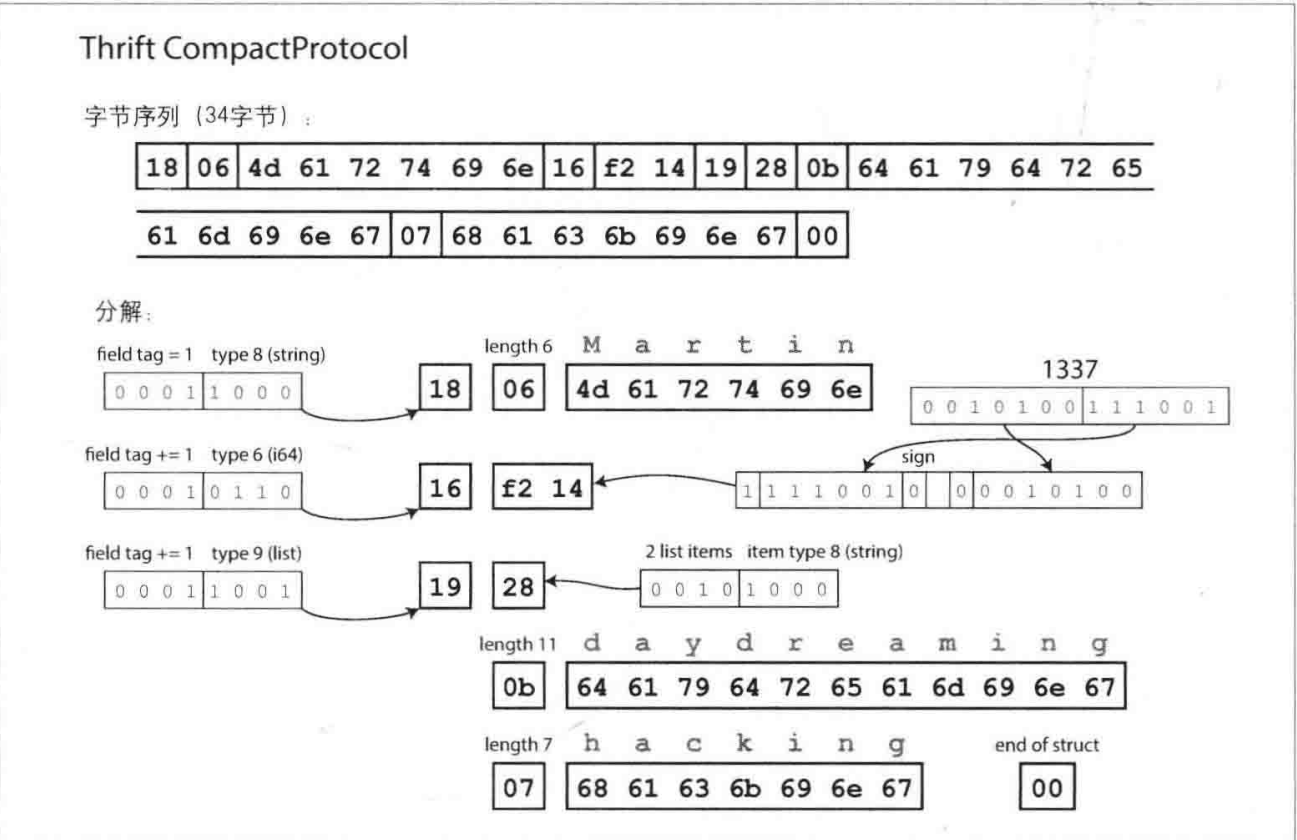
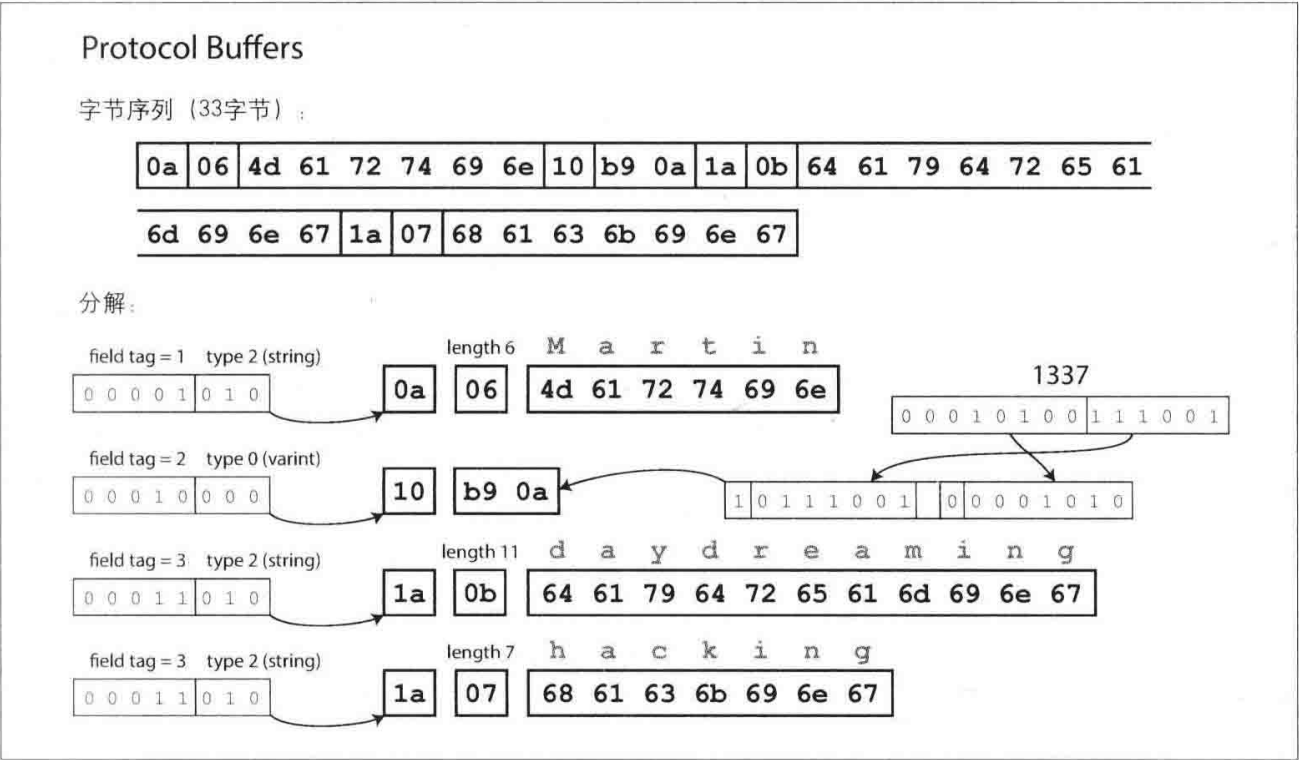
最后,Protocol Buffers (只有一种二进制编码格式) 对相同的数据进行编码。它的位打包方式略有不同,但与Thrift的 CompactProtocol 非常相似
模式演化
之前说过,模式不可避免地需要随着时间而不断变化,称之为模式演化。那么 Thrift 和 Protocol Buffers 如何在保持向后和向前兼容性的同时应对模式更改呢?
每个字段在模式中通过唯一的标签号(field tag)来识别,而不是字段名称,确保了数据的兼容性和一致性。
向前兼容性:
- 字段的添加:可以向模式中添加新字段,赋予新的标签号。如果旧代码遇到未知的标签号,它会忽略这些新字段。这是通过让解析器跳过特定的字节数来实现的,允许旧代码读取新代码写入的数据。
- 删除字段:可以删除可选字段,这样旧代码即使读不到,也可也根据设置使用一个默认值或者简单忽略,如果是必选字段,则会因读不到值而报错
- 更改数据类型:更改字段的数据类型是可能的,但要注意数据可能丢失精度或被截断的风险。例如,将32位整数改为64位整数时,旧代码可能无法处理新数据的完整范围。
向后兼容性:
- 字段的读取:新代码总能读取旧数据,因为每个字段的标签号意义不变。但新添加的字段不能设置为必填(required),因为这会导致新代码在读取旧数据时失败,旧数据中不包含新字段。
- 删除字段:新代码遇到已经删除的字段,它会忽略这些新字段
- 更改数据类型:同向前兼容性一样,肯发生丢失精度或被截断的风险
基于服务的数据流: REST和RPC
对于通过网络进行通信的进程,有许多种通信方式,最常见的两个角色:客户端和服务器,服务器通过网络公开API,客户端可以连接到服务器以向该 API 发出请求,服务器公开的 API 成为服务。
此外,服务器本身可以是另一项服务的客户端 (例如,典型的Web应用服务器作为数据库的客户端) 。这种方法通常用于将大型应用程序按照功能区域分解为较小的服务,这样当一个服务需要另一个服务的某些功能或数据时,就会向另一个服务发出请求。称之为为微服务体系结构 (microservices architecture)。
当 HTTP 被用作与服务通信的底层协议时,它被成为 Web 服务,有两种流行的Web服务方法:REST 和 SOAP
- REST(Representational State Transfer)
REST不是一个具体的协议,而是一种利用HTTP现有功能的架构风格。它主要依赖于HTTP标准的方法来处理数据和交互,比如GET、POST、PUT和DELETE等
1 | import requests |
- SOAP (Simple Object Access Protocol)
SOAP是一种协议,主要通过XML格式的消息进行通信。它不依赖于特定的传输协议,尽管通常使用HTTP,但也可以通过SMTP等其他协议传输SOAP消息。SOAP的设计更偏向于操作和服务,而不是资源。
远程过程调用(RPC)
RPC试图让远程服务调用看起来如同本地函数调用一样简单(称为位置透明性)。然而,这种模式存在许多限制,因为网络调用与本地调用之间存在根本性差异:
- 不可预测性:网络请求受到网络稳定性和远程服务器状态的影响,可能导致请求丢失或延迟。
- 超时和不确定性:网络请求可能因超时而没有结果,与本地调用不同,网络调用的失败可能不会返回任何信息。
- 幂等性问题:如果网络请求失败需要重试,可能会不知不觉中重复执行操作,除非协议中包括了幂等性保护机制。
- 性能问题:网络请求的响应时间比本地函数调用慢并且更加不稳定。
- 数据编码:网络请求需要将参数编码为字节序列,这对于大型对象来说可能成问题。
- 跨语言数据类型转换:RPC框架需要处理不同编程语言之间的数据类型转换,这可能导致兼容性问题。
尽管 RPC 面临多个挑战,但是很多编码都在其基础上构建了各种RPC 框架,例如 Thrift, Avro 带有 RPC 支持 ,gRPC 是使用 Protocol Buffers 的 RPC 实现。
新一代的 RPC 框架更加明确了远程请求与本地函数调用不同的事实。例如,Finagle和Rest.li使用Futures (Promises) 来封装可能失败的异步操作。gRPC支持流,其中调用不仅包括一个请求和一个响应,还包括一段时间内一系列的请求和响应。
其中一些框架还提供了服务发现,即允许客户端查询在哪个IP地址和端口号上获得特定的服务。
目前,REST似乎是公共 API 的主流风格。RPC框架主要侧重于同一组织内多项服务之间的请求,通常发生在同一数据中心内。
基于消息传递的数据流
本章我们一直在研究从一个进程到另一个进程不同的数据流编码方式。到目前为止,已经讨论了 REST 和 RPC (其中一个进程通过网络向另一个进程发送请求) 以及数据库 (其中一个进程写入编码数据,另一个进程在将来某个时刻再次读取该数据) 。
之后我们将简要介绍一下RPC和数据库之间的异步消息传递系统。它们与 RPC 的相似之处在于,客户端的请求 (通常称为消息) 以低延迟传递到另一个进程。它们与数据库的相似之处在于,不是通过直接的网络连接发送销息,而是通过称为消息代理 (也称为消息队列,或面向消息的中间件) 的中介发送的,该中介会暂存消息。
与直接RPC相比,使用消息代理有以下几个优点:
- 如果接收方不可用或过载,它可以充当缓冲区,从而提高系统的可靠性。
- 它可以自动将消息重新发送到崩溃的进程,从而防止消息丢失。
- 它避免了发送方需要知道接收方的IP地址和端口号 (这在虚拟机经常容易起起停停的云部署中特别有用) 。
- 它支持将一条永息发送给多个接收方。
- 它在逻辑上将发送方与接收方分离 (发送方只是发布消息,并不关心谁使用它们) 。
然而,与RPC的差异在于,消息传递通信通常是单向的: 发送方通常不期望收到对其消息的回复。进程可能发送一个响应,但这通常是在一个独立的通道上完成的。这种通信模式是异步的: 发送者不会等待消息被传递,而只是发送然后忘记它。
消息代理
消息代理是一种中间件,用于在不同进程、应用程序或系统之间传递消息。进程通过消息代理将消息发送到队列或主题,消息代理负责确保这些消息可靠地传递给一个或多个目标消费者或订阅者。
传统上由商业软件如TIBCO、IBM WebSphere和WebMethods控制的消息代理市场,近年来已经看到了像RabbitMQ、ActiveMQ、HornetQ、NATS和Apache Kafka等开源软件的兴起。
消息传递模型:消息代理支持单向数据流,其中消费者可以接收消息并可能将其发布到另一个主题或发送到回复队列,支持类似RPC的请求/响应模式。
数据模型的灵活性:消息代理通常不强制使用任何特定的数据模型,而是处理任意编码格式的字节序列。这样的设计允许在不同发布者和消费者间实现高度的灵活性和独立部署。
数据的向后与向前兼容性:为了保持系统组件之间的兼容性和灵活性,建议使用向后与向前兼容的编码格式。如果消费者重新发布消息到另一个主题,需要注意保留消息中的未知字段,以避免数据丢失。
分布式 Actor 模型
Actor模型 是一种用于并发编程的方法,它通过封装逻辑在独立的单元(Actor)中来避免传统多线程编程中常见的问题,如竞争条件、锁定和死锁。
- 在Actor模型中,每个Actor是一个并发单元,持有自己的状态,不与其他Actor共享。
- Actor之间通过异步消息进行通信。这种通信方式不保证消息一定被送达,可能因为错误而丢失。
- 每个Actor一次只处理一条消息,由框架独立调度,因此不需要考虑线程同步问题。
分布式Actor框架 将Actor模型扩展到多个节点,可以跨多个物理或虚拟机环境运行。
- 消息传递:无论Actor位于同一节点还是不同节点,消息传递机制保持一致。如果是跨节点,消息会被编码成字节序列,通过网络发送,并在接收端解码。
- 位置透明性:分布式Actor模型提供了位置透明性,即开发者不需要关心Actor实际运行的物理位置。由于模型本身预期可能会有消息丢失,因此比RPC在处理网络问题上更为鲁棒。
- 版本兼容性:在分布式环境中,如果节点间版本不一致,仍需考虑消息的向前和向后兼容性,特别是在进行滚动升级时。
小结
本章,我们研究了将内存数据结构转换为网络或磁盘上字节流的多种方法。我们看到这些编码的细节不仅影响其效率,更重要的是还影响应用程序的体系结构
特别地,许多服务需要支持滚动升级,即每次将新版本的服务逐步部署到几个节点,而不是同时部署到所有节点。滚动升级允许在不停机的情况下发布新版本的服务 (因此鼓励频繁地发布小版本而不是大版本) ,并降低部署风险 (允许错误版本在影响大量用户之前检测并回滚) 。这些特性非常有利于应用程序的演化和更改。
在滚动升级期间,或者由于各种其他原因,必须假设不同的节点正在运行应用代码的不同版本。因此,在系统内流动的所有数据都需提供向后兼容性(新代码可以读取旧数据) 和向前兼容性 (旧代码可以读取新数据) 。
本章还讨论了多种数据编码格式及其兼容性情况:
- 编程语言特定的编码仅限于某一种编程语言,往往无法提供向前和向后兼容性。
- JSON、XMIL和CSV等文本格式非常普遍,其兼容性取决于你如何使用他们。它们有可选的模式语言,必须小心处理数字和二进制字符串等问题。
- 像Thrift、Protocol Buffers和Avro这样的二进制的模式驱动格式,支持使用清晰定义的向前和向后兼容性语义进行紧凑、高效的编码。这些模式对于静态类型语言中的文档和代码生成非常有用。然而,它们有一个缺点,即只有在数据解码后才是人类可读的。
我们还讨论了数据流的几种模型,说明了数据编码在不同场景下非常重要:
- 数据库,写入数据库的进程对数据进行编码,而读取数据库的进程对数据进行解码。
- RPC 和REST API,其中客户端对请求进行编码,服务器对请求进行解码并对响应进行编码,客户端最终对响应进行解码。
- 异步消息传递 (使用消息代理或Actor) ,节点之间通过互相发送消息进行通信,消息由发送者编码并由接收者解码。




